课程简介

轻松入门大数据 一站式完成核心能力构建视频课程,由乐学编程课堂网精心整理发布高清完结版。本课带你零基础入门大数据,从理论入门到环境搭建,从小案例到大项目,从方案到思维,稳扎稳打掌握大数据技能。深度讲解底层源码,透彻理解设计思路。手把手带你完成一个大型项目的搭建,理论+案例+实操快速提升实战能力。
相关课程

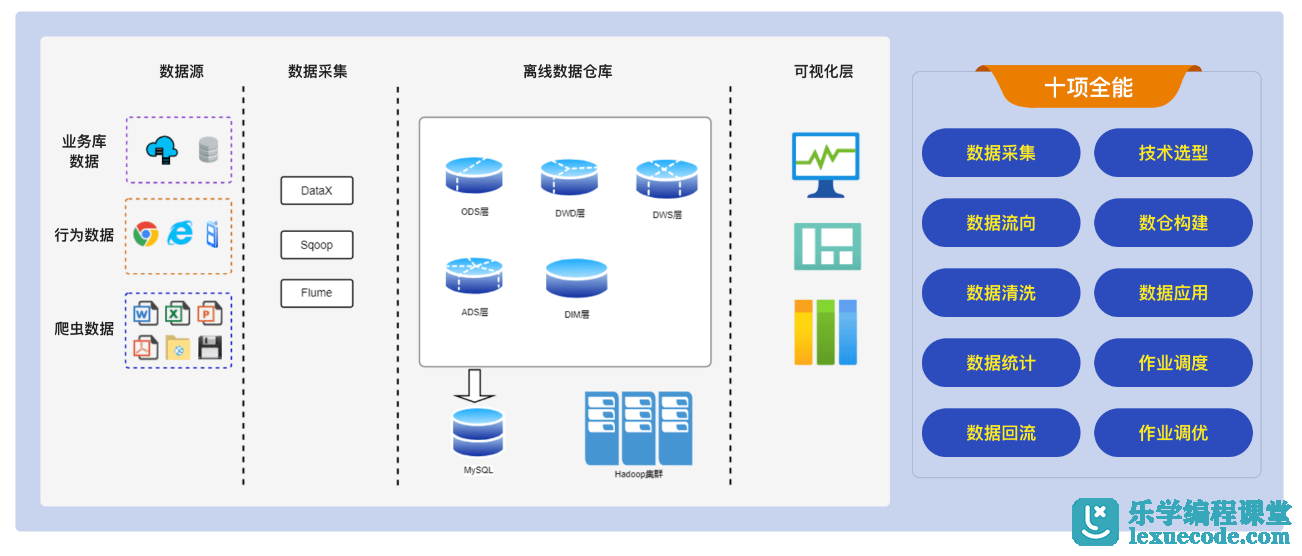
构建企业级大数据离线数据仓库:离线数仓被广泛应用于电商、安全、教育等行业,通过数据的整合与调度,可以直观发现问题,作出高效决策。
课程实战项目
疫情防控接触大数据分析系统可以很好的帮助管理人员查看各区县教育局及其.下属学校学生、老师的健康问卷提交情况,和师生的健康状况,直观的展示辖区内学生老师红黄绿码的人数,更好的帮助疫情防控管理。

作业管理预警系统为教育局领导、老师专门打造,可以通过大屏了解学生的作业情况,支持包括学校、年级、班级、学科纬度在内的作业完成数据查看,实时查看老师的作业布置及学生作业完成情况。

内容分发系统通过广泛的网络节点分布,提供快速、稳定、安全、可编程的全球内容分发加速服务,支持将网站、音视频、下载等内容分发至接近用户的节点,使用户可就近取得所需内容,提高用户访问的响应速度和成功率。

课程目录
├── 第1章 大数据,比你更懂你自己/
│ ├── [ 35M] 1-1 为什么大数据行业更有钱途?
│ ├── [2.8M] 1-2 本章学习安排
│ ├── [ 33M] 1-3 什么是大数据
│ ├── [ 24M] 1-4 大数据特点(4V)
│ ├── [ 29M] 1-5 大数据带来的变革
│ ├── [6.4M] 1-6 大数据应用场景
│ ├── [ 25M] 1-7 大数据前景
│ └── [8.0M] 1-8 大数据学习方法论
├── 第2章 初识Hadoop/
│ ├── [2.7M] 2-1 课程目录
│ ├── [ 76M] 2-2 Hadoop概述
│ ├── [100M] 2-3 Hadoop发展史(了解)
│ ├── [ 66M] 2-4 认识Hadoop三大核心组件
│ ├── [ 50M] 2-5 大数据生态圈
│ └── [ 24M] 2-6 发行版的选择
├── 第3章 Hadoop之HDFS篇/
│ ├── [5.3M] 3-1 课程目录
│ ├── [ 63M] 3-10 Hadoop解压及重要目录讲解
│ ├── [114M] 3-11 HDFS核心配置文件及免密码登陆
│ ├── [143M] 3-12 HDFS启停(整体和单个)
│ ├── [ 13M] 3-13 环境变量补充
│ ├── [ 57M] 3-14 初识HDFS常用命令
│ ├── [104M] 3-15 HDFS命令行操作之文件上传
│ ├── [ 19M] 3-16 HDFS命令行操作之文件内容查看
│ ├── [ 22M] 3-17 HDFS命令行操作之文件下载
│ ├── [ 70M] 3-18 HDFS命令行操作之其他常用操作
│ ├── [ 43M] 3-19 HDFS API开发之基本环境介绍
│ ├── [ 63M] 3-20 jUnit快速入门
│ ├── [ 39M] 3-21 jUnit生命周期(上)
│ ├── [ 45M] 3-22 jUnit生命周期(下)
│ ├── [157M] 3-23 HDFS API开发之创建文件夹
│ ├── [125M] 3-24 HDFS API开发之上传文件
│ ├── [121M] 3-25 HDFS API开发之参数优先级问题
│ ├── [ 59M] 3-26 HDFS API开发之文件下载和重命名
│ ├── [ 86M] 3-27 HDFS API开发之代码重构
│ ├── [132M] 3-28 HDFS API开发之列表展示功能
│ ├── [ 22M] 3-29 HDFS API开发之删除操作
│ ├── [108M] 3-3 初识HDFS
│ ├── [ 99M] 3-30 HDFS API开发之基于IO流的方式
│ ├── [112M] 3-31 【重要!必掌握】经典面试题之HDFS写数据流程
│ ├── [ 52M] 3-32 【重要!必掌握】经典面试题之HDFS读数据流程
│ ├── [ 92M] 3-33 【重要!必掌握】NameNode&SecondaryNameNode工作机制(上)
│ ├── [153M] 3-34 【重要!必掌握】NameNode&SecondaryNameNode工作机制(下)
│ ├── [156M] 3-35 【重要!必掌握】DataNode工作机制
│ ├── [ 98M] 3-36 安全模式
│ ├── [251M] 3-4 HDFS假设和目标
│ ├── [145M] 3-5 【重要!必掌握】HDFS架构
│ ├── [ 54M] 3-6 文件系统命名空间
│ ├── [131M] 3-7 副本因子及副本拜访策略
│ ├── [ 29M] 3-8 【重要!必掌握】经典面试题
│ └── [9.9M] 3-9 HDFS优缺点
├── 第4章 Hadoop之MapReduce篇/
│ ├── [ 26M] 4-1 课程目录
│ ├── [138M] 4-10 词频统计之自定义Mapper
│ ├── [ 87M] 4-11 词频统计之自定义Reducer
│ ├── [101M] 4-12 词频统计之自定义Driver
│ ├── [101M] 4-13 词频统计之测试及重构
│ ├── [268M] 4-14 词频统计之Mapper源码分析
│ ├── [ 79M] 4-15 词频统计之Reducer源码分析
│ ├── [115M] 4-16 词频统计之模板方法模式
│ ├── [ 69M] 4-17 序列化概述【乐学编程网 lexuecode.com】
│ ├── [ 95M] 4-18 序列化之JDK自带的序列化机制
│ ├── [122M] 4-19 序列化之Data序列化机制
│ ├── [109M] 4-2 初识MapReduce框架
│ ├── [112M] 4-20 Hadoop序列化之Writable接口详解
│ ├── [141M] 4-21 Hadoop序列化之需求分析
│ ├── [ 58M] 4-22 Hadoop序列化之自定义序列化类
│ ├── [ 77M] 4-23 Hadoop序列化之自定义Mapper类
│ ├── [ 51M] 4-24 Hadoop序列化之自定义Reducer类
│ ├── [173M] 4-25 Hadoop序列化之自定义Driver类及测试
│ ├── [ 67M] 4-26 Hadoop序列化之总结
│ ├── [269M] 4-27 初识InputFormat&InputSplit
│ ├── [ 85M] 4-28 InputSplit和Block的关系
│ ├── [248M] 4-29 本地IDEA运行时InputSplit的大小测试
│ ├── [118M] 4-3 MapReduce框架的优缺点
│ ├── [ 66M] 4-30 认识FileInputFormat
│ ├── [139M] 4-31 TextInputFormat编程
│ ├── [206M] 4-32 KeyValueTextInputFormat编程
│ ├── [202M] 4-33 NLineInputFormat编程
│ ├── [275M] 4-34 DBInputFormat编程
│ ├── [201M] 4-35 Partitioner功能及编程
│ ├── [ 66M] 4-36 本地预计算Combiner意义
│ ├── [166M] 4-37 本地预计算Combiner编程
│ ├── [112M] 4-38 排序概述
│ ├── [148M] 4-39 排序之全局排序编程
│ ├── [ 81M] 4-4 【重要!必掌握】MapReduce思想
│ ├── [ 83M] 4-40 排序之分区排序编程
│ ├── [184M] 4-41 通过源码认识OutputFormat
│ ├── [193M] 4-42 OutputFormat编程之输出数据到MySQL表中
│ ├── [326M] 4-43 OutputFormat编程之自定义OutputFormat
│ ├── [177M] 4-44 MapReduce全流程之MapTask工作原理
│ ├── [ 80M] 4-45 MapReduce全流程之ReduceTask工作原理
│ ├── [ 30M] 4-46 MapReduce全流程之Shuffle工作原理
│ ├── [330M] 4-47 MapReduce全流程之调优
│ ├── [ 71M] 4-48 MapReduce全流程之加强
│ ├── [ 64M] 4-49 场景题之group by需求分析
│ ├── [ 36M] 4-5 MapReduce核心进程
│ ├── [103M] 4-50 场景题之group by功能开发及测试
│ ├── [ 28M] 4-51 场景题之distinct需求分析
│ ├── [ 50M] 4-52 场景题之distinct功能实现及测试
│ ├── [ 62M] 4-53 场景题之ReduceJoin需求分析
│ ├── [ 71M] 4-54 场景题之ReduceJoin自定义序列化类
│ ├── [283M] 4-55 场景题之ReduceJoin功能开发及测试
│ ├── [ 37M] 4-56 场景题之ReduceJoin的弊端
│ ├── [ 62M] 4-57 场景题之MapJoin原理分析
│ ├── [287M] 4-58 场景题之MapJoin功能实现及测试
│ ├── [180M] 4-59 基于MR编程开发核心组件系统性梳理
│ ├── [234M] 4-6 官方词频统计案例分析
│ ├── [ 20M] 4-7 词频统计数据流图解
│ ├── [122M] 4-8 MapReduce编程规范
│ └── [ 50M] 4-9 初识MR编程中的数据类型
├── 第5章 Hadoop之YARN篇/
│ ├── [4.2M] 5-1 课程目录
│ ├── [ 46M] 5-10 开启作业历史服务器
│ ├── [182M] 5-11 YARN命令(掌握使用方法)
│ ├── [ 78M] 5-12 【重要!必掌握】打包自己开发的作业到YARN上运行
│ ├── [ 44M] 5-13 初识YARN调度器
│ ├── [6.7M] 5-14 调度器之FIFO
│ ├── [218M] 5-15 调度器之CapacityScheduler深入详解
│ ├── [216M] 5-16 【重要!必掌握】调度器之CapacityScheduler队列配置及测试
│ ├── [ 32M] 5-17 【重要!必掌握】调度器之CapacityScheduler优先级配置及测试
│ ├── [ 86M] 5-2 YARN产生背景
│ ├── [ 96M] 5-3 YARN架构核心组件
│ ├── [229M] 5-4 【重要!必掌握】YARN核心组件职责
│ ├── [ 98M] 5-5 【重要!必掌握】YARN工作原理
│ ├── [ 28M] 5-6 YARN容错性
│ ├── [ 16M] 5-7 以YARN为核心的生态系统
│ ├── [ 33M] 5-8 YARN单节点部署
│ └── [ 82M] 5-9 提交官方自带案例到YARN上运行并认识YARN UI界面
├── 第6章 分布式协调服务ZooKeeper/
│ ├── [5.7M] 6-1 课程目录
│ ├── [ 50M] 6-10 【重要!必掌握】ZK监听器实操
│ ├── [119M] 6-11 ZK命令行详解之四字命令
│ ├── [ 14M] 6-12 ZK集群核心概念
│ ├── [242M] 6-13 ZK单节点多Server部署及HA测试
│ ├── [ 60M] 6-2 初识ZK
│ ├── [114M] 6-3 ZK角色及选举机制
│ ├── [ 53M] 6-4 ZK在企业中的使用场景
│ ├── [ 97M] 6-5 ZK单机单Server部署
│ ├── [ 30M] 6-6 【重要!必掌握】ZK数据模型
│ ├── [ 81M] 6-7 ZK命令行详解之创建
│ ├── [ 38M] 6-8 ZK命令行详解之修改和删除
│ └── [ 10M] 6-9 初识ZK中的监听器
├── 第7章 Hadoop集群篇/
│ ├── [6.9M] 7-1 课程目录
│ ├── [ 25M] 7-2 从单机版引入到集群版
│ ├── [114M] 7-3 Hadoop集群规划及准备工作
│ ├── [153M] 7-4 Hadoop集群部署及测试
│ ├── [399M] 7-5 Hadoop HA架构
│ ├── [ 65M] 7-6 ZK分布式环境部署
│ └── [176M] 7-7 Hadoop集群HDFS HA配置及测试
├── 第8章 初识Hive/
│ ├── [3.7M] 8-1 课程目录
│ ├── [ 25M] 8-10 Hive访问方式之HS2&beeline
│ ├── [ 46M] 8-11 【重要!必掌握】Hive中两个重要参数的用法
│ ├── [ 76M] 8-2 Hive产生背景
│ ├── [151M] 8-3 Hive是什么
│ ├── [ 39M] 8-4 Hive的优缺点
│ ├── [147M] 8-5 【重要!必掌握】Hive架构
│ ├── [ 36M] 8-6 Hive部署架构
│ ├── [ 96M] 8-7 经典面试题
│ ├── [196M] 8-8 Hive部署及快速使用
│ └── [125M] 8-9 Hive中参数的设置和使用
└── 第9章 Hive DDL&DML/
├── [4.4M] 9-1 课程目录
├── [ 54M] 9-10 经典面试题分析之内外部表转换问题
├── [ 44M] 9-11 【重要!必掌握】经典面试题分析之内外部表对比及使用场景
├── [ 74M] 9-12 DDL之修改表实操
├── [ 33M] 9-13 经典面试题之drop和truncate的区别
├── [324M] 9-14 【重要!必掌握】DML之表数据加载的N种姿势
├── [ 58M] 9-15 经典面试题之为什么不使用insert values的写法呢
├── [ 92M] 9-16 DML之通过SQL导出数据
├── [ 55M] 9-17 【重要!必掌握】DML之export&import实操
├── [ 28M] 9-18 关于truncate的思考题
├── [ 45M] 9-19 分区表意义何在
├── [ 23M] 9-2 【重要!必掌握】Hive数据模型
├── [195M] 9-20 分区表实操之单分区表创建及数据加载
├── [ 35M] 9-21 分区表实操之多级分区表创建及数据加载
├── [122M] 9-22 场景题之使用动态分区解决复杂问题
├── [ 69M] 9-23 SQL查询之基础使用
├── [ 18M] 9-24 SQL查询之聚合函数的使用
├── [ 52M] 9-25 【重要!必掌握】SQL查询之分组函数的使用
├── [116M] 9-26 【重要!必掌握】SQL查询之JOIN的使用
├── [113M] 9-3 DDL之创建数据库
├── [ 61M] 9-4 DDL之修改和删除数据库
├── [ 50M] 9-5 Hive数据类型&分隔符
├── [115M] 9-6 DDL之创建表语法
├── [ 93M] 9-7 DDL之创建表实操
├── [ 51M] 9-8 经典面试题分析之内部表
└── [ 39M] 9-9 经典面试题分析之外部表
├── 第10章 Hive函数篇/
│ ├── [4.8M] 10-1 课程目录
│ ├── [ 63M] 10-10 动手实操URL函数的使用
│ ├── [ 25M] 10-11 动手实操NVL函数的使用
│ ├── [169M] 10-12 动手实操场景题之条件控制函数的使用
│ ├── [ 61M] 10-13 【重要!必掌握】动手实操场景题之行列转换功能一
│ ├── [ 95M] 10-14 【重要!必掌握】动手实操场景题之行列转换功能二
│ ├── [ 43M] 10-15 【重要!必掌握】动手实操场景题之使用Hive完成wc统计
│ ├── [ 17M] 10-16 初识Hive UDF函数
│ ├── [ 52M] 10-17 动手实操开发自定义UDF函数之UDF实现类的开发
│ ├── [133M] 10-18 【重要!必掌握】动手实操开发自定义UDF函数之UDF临时函数的注册和使用
│ ├── [ 64M] 10-19 【重要!必掌握】动手实操开发自定义UDF函数之UDF永久函数的注册和使用
│ ├── [129M] 10-2 动手实操复杂数据类型之array
│ ├── [ 94M] 10-20 自定义UDF扩展之如何集成Hive源码进行二次开发
│ ├── [167M] 10-21 动手实操开发自定义UDF函数之新版本UDF开发及使用
│ ├── [143M] 10-22 动手实操开发自定义UDTF函数开发及使用
│ ├── [335M] 10-23 【重要!必掌握】窗口分析函数场景sum over的使用
│ ├── [ 78M] 10-24 窗口分析函数场景NTILE的使用
│ ├── [ 97M] 10-25 【重要!必掌握】窗口分析函数场景row_number&rank&dense_rank的使用
│ ├── [142M] 10-26 窗口分析函数场景lag&lead的使用
│ ├── [ 39M] 10-27 窗口分析函数场景firstvalue&lastvalue的使用
│ ├── [129M] 10-28 窗口分析函数场景cume_dist&precent_rank的使用
│ ├── [ 50M] 10-29 动手实操之窗口函数综合使用
│ ├── [185M] 10-3 动手实操复杂数据类型之map
│ ├── [ 61M] 10-4 动手实操复杂数据类型之struct
│ ├── [ 38M] 10-5 如何去挖掘Hive中内置函数使用的方法论
│ ├── [210M] 10-6 动手实操日期时间函数的使用
│ ├── [ 53M] 10-7 动手实操取整相关函数的使用
│ ├── [108M] 10-8 动手实操字符串相关函数的使用
│ └── [185M] 10-9 动手实操场景题之处理json数据
├── 第11章 Hive调优篇/
│ ├── [5.0M] 11-1 课程目录
│ ├── [ 63M] 11-10 Hive4大by总结
│ ├── [ 40M] 11-11 Hive并行执行的适用场景
│ ├── [ 58M] 11-12 Hive推测式执行能为我们带来的利弊
│ ├── [110M] 11-13 Hive如何设置合理的MapTask数量
│ ├── [100M] 11-14 Hive如何设置合理的ReduceTask数量
│ ├── [ 37M] 11-15 分布式计算框架中产生数据倾斜的根本原因
│ ├── [107M] 11-16 场景之groupby的数据倾斜解决方案
│ ├── [ 94M] 11-17 场景之count(disintct)的数据倾斜解决方案
│ ├── [146M] 11-18 场景之join的数据倾斜解决方案
│ ├── [ 33M] 11-2 Hive调优概述
│ ├── [132M] 11-3 Hive作业什么时候跑MR作业
│ ├── [ 65M] 11-4 Hive作业如何以本地方式运行
│ ├── [ 56M] 11-5 Hive严格模式带来的好处
│ ├── [ 47M] 11-6 Hive4大by之order by
│ ├── [ 94M] 11-7 Hive4大by之sort by
│ ├── [110M] 11-8 Hive4大by之distribute by
│ └── [ 46M] 11-9 Hive4大by之cluster by
├── 第12章 初识Flume/
│ ├── [4.4M] 12-1 课程目录
│ ├── [109M] 12-10 Agent启动及测试
│ ├── [ 22M] 12-11 数据传输基本单元Event
│ ├── [ 60M] 12-2 Flume产生背景
│ ├── [ 48M] 12-3 采集vs收集
│ ├── [144M] 12-4 初识Flume及学习姿势
│ ├── [ 53M] 12-5 竞品分析
│ ├── [ 14M] 12-6 发展史
│ ├── [144M] 12-7 【重要!必掌握】Flume核心组件
│ ├── [152M] 12-8 Flume Agent配置文件编写指南
│ └── [ 44M] 12-9 Flume部署
├── 第13章 Flume进阶实操/
│ ├── [7.4M] 13-1 课程目录
│ ├── [ 32M] 13-10 认识Sink Processor
│ ├── [176M] 13-11 【重要!必掌握】实战之Sink Processor
│ ├── [382M] 13-2 实战之监控某个文件新增的内容并输出到HDFS
│ ├── [427M] 13-3 实战之监控某个文件夹下新增的内容并输出到HDFS
│ ├── [263M] 13-4 实战之监控某个文件夹下新增的内容并输出到HDFS分区中
│ ├── [175M] 13-5 【重要!必掌握】实战之TAILDIR断点续传收集数据
│ ├── [ 25M] 13-6 【重要!必掌握】生产场景理解
│ ├── [220M] 13-7 avrosink和avrosource配对使用
│ ├── [ 80M] 13-8 认识Channel Selector
│ └── [104M] 13-9 【重要!必掌握】实战之Channel Selector
├── 第14章 初识Scala/
│ ├── [2.7M] 14-1 课程目录
│ ├── [114M] 14-2 Scala是什么
│ ├── [ 25M] 14-3 学习Scala的意义何在
│ ├── [ 61M] 14-4 Scala安装及快速使用
│ ├── [ 44M] 14-5 Scala与JVM的关系
│ └── [ 85M] 14-6 基于IDEA构建Scala项目
├── 第15章 Scala语言基础/
│ ├── [7.5M] 15-1 课程目录
│ ├── [ 61M] 15-10 运算符的用法
│ ├── [180M] 15-11 条件分支详解
│ ├── [120M] 15-12 循环之while&dowhile
│ ├── [ 87M] 15-13 循环之while以优雅的方式退出
│ ├── [286M] 15-14 【重要!必掌握】循环之for
│ ├── [ 42M] 15-15 通过场景引出方法
│ ├── [114M] 15-16 【重要!必掌握】方法的定义和使用
│ ├── [ 83M] 15-17 【重要!必掌握】 默认参数
│ ├── [ 62M] 15-18 命名参数
│ ├── [101M] 15-19 【重要!必掌握】变长参数
│ ├── [223M] 15-2 注释之论一个码农的自我修养
│ ├── [ 95M] 15-20 数据类型补充之Unit&Null&Nothing
│ ├── [225M] 15-3 标识符之论起名的艺术
│ ├── [ 25M] 15-4 宏观了解Scala中的数据类型
│ ├── [137M] 15-5 值和变量(注意理解第二个场景)
│ ├── [139M] 15-6 数据类型
│ ├── [ 98M] 15-7 数据类型转换
│ ├── [156M] 15-8 【重要!必掌握】字符串操作
│ └── [ 87M] 15-9 实操之从控制台终端获取数据
├── 第16章 Scala面向对象编程/
│ ├── [7.5M] 16-1 课程目录
│ ├── [293M] 16-10 【重要!必掌握】伴生类&伴生对象
│ ├── [140M] 16-11 从面试题说起case class&case object
│ ├── [223M] 16-12 trait的定义及使用
│ ├── [133M] 16-13 动态混入&自身类型
│ ├── [165M] 16-14 包管理以及隐式转换导入
│ ├── [ 90M] 16-15 【重要!必掌握】packageobject的使用
│ ├── [147M] 16-16 类型转换&类型判断&类型别名
│ ├── [ 56M] 16-17 枚举的使用
│ ├── [ 61M] 16-18 App小技巧的使用
│ ├── [ 62M] 16-2 面向对象三大特性
│ ├── [ 41M] 16-3 【重要!必掌握】通过女朋友认识类和对象的关系
│ ├── [152M] 16-4 定义类并通过反编译掌握属性对应的方法构成
│ ├── [ 38M] 16-5 【重要!必掌握】占位符在Scala中的使用
│ ├── [ 39M] 16-6 通过反编译掌握private关键字的使用
│ ├── [132M] 16-7 构造器与附属构造器的使用及阅读源码
│ ├── [212M] 16-8 继承&重写的使用及阅读源码
│ └── [149M] 16-9 抽象类的使用及阅读源码
├── 第17章 Scala集合/
│ ├── [8.6M] 17-1 课程目录
│ ├── [ 74M] 17-10 可变Map的定义和使用
│ ├── [163M] 17-2 Scala集合架构
│ ├── [195M] 17-3 不可变数组的定义和使用【乐学编程网 lexuecode.com】
│ ├── [200M] 17-4 【重要!必掌握】可变数组的定义和使用
│ ├── [171M] 17-5 不可变和可变Set的定义和使用
│ ├── [162M] 17-6 【重要!必掌握】不可变和可变List的定义和使用
│ ├── [ 94M] 17-7 List方法的补充
│ ├── [197M] 17-8 【重要!必掌握】Tuple的定义和使用
│ └── [139M] 17-9 【重要!必掌握】不可变Map的定义和使用及使用注意事项
├── 第18章 Scala模式匹配/
│ ├── [ 12M] 18-1 课程目录
│ ├── [ 80M] 18-10 模式匹配之List匹配
│ ├── [ 60M] 18-11 模式匹配之class匹配
│ ├── [ 23M] 18-12 【重要!必掌握】模式匹配之caseclass匹配
│ ├── [ 57M] 18-13 模式匹配之结合Spark讲解
│ ├── [ 93M] 18-14 模式匹配之Scala异常处理
│ ├── [114M] 18-15 初识偏函数
│ ├── [161M] 18-16 【重要!必掌握】偏函数剥丝抽茧迭代
│ ├── [ 31M] 18-2 隐式转换能为我们带来什么
│ ├── [ 21M] 18-3 模式匹配概念的理解
│ ├── [ 61M] 18-4 模式匹配之快速上手
│ ├── [ 66M] 18-5 模式匹配之内容匹配
│ ├── [ 74M] 18-6 模式匹配之守卫模式
│ ├── [105M] 18-7 模式匹配之类型匹配
│ ├── [ 99M] 18-8 模式匹配之Array匹配
│ └── [ 27M] 18-9 模式匹配之Tuple匹配
├── 第19章 Scala函数式编程/
│ ├── [ 13M] 19-1 课程目录
│ ├── [ 43M] 19-10 高阶算子详解之reduce&reduceLeft&reduceRight(一定要体会中间过程的理解)
│ ├── [ 56M] 19-11 高阶算子详解之fold&foldLeft&foldRight(一定要体会中间过程的理解)
│ ├── [ 62M] 19-12 高阶算子详解之zip系列
│ ├── [110M] 19-13 高阶算子详解之groupBy
│ ├── [ 28M] 19-14 高阶算子详解之mapValues
│ ├── [161M] 19-15 高阶算子详解之排序系列
│ ├── [ 91M] 19-16 高阶算子详解之算子综合实操
│ ├── [ 18M] 19-17 注意一个小小的面试题
│ ├── [117M] 19-2 经典面试题之函数和方法的区别
│ ├── [122M] 19-3 【重要!必掌握】方法与函数的转换
│ ├── [132M] 19-4 【重要!必掌握】高阶函数定义及使用
│ ├── [ 49M] 19-5 Currying定义及使用
│ ├── [257M] 19-6 【重要!必掌握】经典面试题之自定义实现一些高阶算子
│ ├── [130M] 19-7 高阶算子详解之map
│ ├── [136M] 19-8 高阶算子详解之filter&foreach&结合map的综合使用
│ └── [101M] 19-9 高阶算子详解之flatter&flatMap
├── 第20章 Scala隐式转换/
│ ├── [9.0M] 20-1 课程目录
│ ├── [ 31M] 20-2 隐式转换能为我们带来什么
│ ├── [144M] 20-3 【重要!必掌握】 隐式转换函数的定义和使用
│ ├── [ 73M] 20-4 【重要!必掌握】隐式转换函数的封装
│ ├── [119M] 20-5 隐式类的定义和使用
│ ├── [ 32M] 20-6 隐式类的封装
│ └── [139M] 20-7 隐式参数的定义和使用
├── 第21章 Scala泛型/
│ ├── [4.7M] 21-1 课程目录
│ ├── [110M] 21-2 Java泛型基础回顾
│ ├── [ 70M] 21-3 Java泛型上下限回顾
│ ├── [149M] 21-4 Java中两种不同的排序
│ ├── [109M] 21-5 Scala中泛型类的定义和使用
│ ├── [ 85M] 21-6 Scala泛型上下限
│ ├── [159M] 21-7 【重要!必掌握】Scala视图界定
│ ├── [102M] 21-8 【重要!必掌握】Scala泛型结合隐式转换的使用
│ └── [ 43M] 21-9 Scala中的逆变和协变
├── 第22章 Scala通信项目实战/
│ ├── [8.6M] 22-1 课程目录
│ ├── [127M] 22-10 功能实现之NN定期检查超时的DN并移除
│ ├── [ 39M] 22-11 功能实现之单机器多进程方式测试
│ ├── [ 31M] 22-2 Akka概述
│ ├── [118M] 22-3 剖析Actor模型工作机制
│ ├── [ 25M] 22-4 需求分析
│ ├── [175M] 22-5 功能实现之启动NN和DN
│ ├── [ 72M] 22-6 功能实现之DN向NN建立连接并发送注册消息
│ ├── [ 93M] 22-7 功能实现之封装消息
│ ├── [ 40M] 22-8 功能实现之NN向DN发送注册成功消息
│ └── [127M] 22-9 功能实现之DN周期性的向NN发送心跳消息
├── 第23章 Hadoop离线数仓项目实战/
│ ├── [4.8M] 23-1 课程目录
│ ├── [105M] 23-10 NameNode启动流程梳理
│ ├── [135M] 23-11 NameNode资源检查
│ ├── [107M] 23-12 NameNode心跳检测
│ ├── [150M] 23-13 NameNode安全模式
│ ├── [218M] 23-14 DataNode启动宏观流程梳理
│ ├── [202M] 23-15 startDataNode方法梳理【乐学编程网 lexuecode.com】
│ ├── [134M] 23-16 初始化DataXceiverServer&DatanodeHttpServer&RPCServer
│ ├── [331M] 23-17 DataNode向NameNode注册
│ ├── [226M] 23-18 DataNode和NameNode的心跳处理
│ ├── [349M] 23-19 MR作业提交流程源码分析
│ ├── [ 32M] 23-2 初识RPC
│ ├── [232M] 23-20 MR作业提交流程小结
│ ├── [350M] 23-21 MR作业提交流程之切片源码分析
│ ├── [270M] 23-22 MapTask&ReduceTask执行流程源码分析
│ ├── [204M] 23-23 提交作业到YARN上执行分析
│ ├── [202M] 23-3 自定义RPC协议实现
│ ├── [305M] 23-4 如何以正确的姿势阅读源码&NN职责
│ ├── [ 98M] 23-5 NameNode入口点函数
│ ├── [234M] 23-6 NameNode核心成员变量初始化
│ ├── [112M] 23-7 NameNodeHttpServer创建及启动
│ ├── [119M] 23-8 加载命名空间
│ └── [ 94M] 23-9 创建NameNodeRpcServer
├── 第24章 Hadoop源码分析/
│ ├── [5.3M] 24-1 课程目录
│ ├── [119M] 24-10 processCmd方法剖析
│ ├── [148M] 24-11 processLocalCmd方法剖析
│ ├── [ 24M] 24-12 SQL执行流程剖析
│ ├── [162M] 24-13 逻辑执行计划&物理执行计划剖析
│ ├── [118M] 24-14 compile方法剖析
│ ├── [ 76M] 24-15 analyze方法剖析
│ ├── [164M] 24-16 execute方法剖析
│ ├── [164M] 24-17 Hive源码分析总结
│ ├── [108M] 24-2 源码分析准备工作
│ ├── [125M] 24-3 hiveconf的用法
│ ├── [ 83M] 24-4 hivevar的用法
│ ├── [ 27M] 24-5 !的用法
│ ├── [139M] 24-6 寻找源码入口点
│ ├── [173M] 24-7 CliDriver的run方法详解
│ ├── [ 93M] 24-8 prompt的使用
│ └── [142M] 24-9 executeDriver方法剖析
├── 第25章 Hive源码篇/
│ ├── [8.2M] 25-1 课程目录
│ ├── [109M] 25-10 创建Hive表并加载数据到表中
│ ├── [ 86M] 25-11 维度指标分析
│ ├── [ 87M] 25-12 通过JDBC查询Hive中的统计结果
│ ├── [ 79M] 25-13 现在的处理方式引出的问题
│ ├── [265M] 25-14 【重要】数仓分层(上)
│ ├── [188M] 25-15 【重要】数仓分层(下)
│ ├── [253M] 25-16 脚本封装etl及加载到hive表
│ ├── [ 59M] 25-17 ODS层改进方案
│ ├── [ 43M] 25-18 shell脚本补充
│ ├── [ 53M] 25-19 调优之压缩能为我们带来什么
│ ├── [ 77M] 25-2 大数据离线处理架构分析(上)
│ ├── [166M] 25-20 调优之压缩如何选型
│ ├── [257M] 25-21 调优之压缩的代码实现方式
│ ├── [299M] 25-22 调优之压缩在MR中的使用
│ ├── [157M] 25-23 调优之压缩在Hive中的使用
│ ├── [197M] 25-24 调优之存储格式的使用(TextFile&RCFile)
│ ├── [128M] 25-25 调优之存储格式的使用(ORC&Parquet)
│ ├── [ 63M] 25-26 DWD层创建
│ ├── [124M] 25-27 DWS&ADS层统计
│ ├── [ 31M] 25-28 指标补充
│ ├── [ 82M] 25-3 大数据离线处理架构分析(下)
│ ├── [171M] 25-4 CDN日志及指标了解
│ ├── [201M] 25-5 日志类定义
│ ├── [303M] 25-6 日志解析
│ ├── [356M] 25-7 使用MR完成数据清洗功能
│ ├── [105M] 25-8 数据质量指标统计
│ └── [139M] 25-9 数据清洗作业提交到YARN上运行
└── 资料代码/
更新日志
2022-11-11:已更新完结,百度云盘下载。







